Mechanism Design
In the early stage of algorithm design, the goal was to solve exacly and efficiently the combinatorial problems. Cook’s Theorem and the NP-completeness theory showed us that some problems are inehently hard. How can we solve this problem? By trying to find approximated solutions or by trying to look at restricted instances of those problems that are tractable. It turns out that the lack of computational power (NP-hardness in some sense) is not the only obstracle to solving problems optimally. Online algorithms propose a model where the difficulty is due to lack of information. The algorithm must take some decisions before seeing the entire input. Again, in most of the cases it is hopeless to get an optimal solution (the solution we could get if we knew the input ahead of time) and our goal is not to be far from it. Other example of natural limitation are streaming algorithms, where you should solve a certain problem with limited memory. Imagine for example one algorithm that runs in a router, that received gigabits each second. It is impossible to store all the information, and yet, we want to process this very very large input and give an anwer at some point.
An additional model is inspired in economy: there are a bunch of agents which have part of the input to the algorithm and they are interested in the solution, say, they have a certain value for each final outcome. Now, they will release their part of the input. The may lie about it to manipulate the final result according to their own interest. How to prevent that? We need to augment the algorithm with some economic incentives to make sure they don’t harm the final solution too much. We need to care about two things now: we still want a solution not to far from the optimal, but we also need to provide incentives. Such algorithm with incentives is called a mechanism and this represents one important field in Algorithmic Game Theory called Mechanism Design.
The simplest setting where this can occur is in a matching problem. Suppose there are 



One of the most famous early papers in this are is the “Optimal Design Auction” by Myerson where he discusses auctions mechanisms that maximize the profit for the seller. After reading some papers in this area, I thought I should return and read the original paper by Myerson, and it was indeed a good idea, since the paper formalizes (or makes very explicit) a lot of central concept in this area. I wanted to blog about the two main tools in mechanism design discussed in the paper: the revelation principle and the revenue equivalence theorem.
Revelation Principle
We could imagine thousands of possible ways of providing economic incentives. It seems a difficult task to look at all possible mechanisms and choose the best one. The good thing is: we don’t need to look at all kinds of mechanisms: we can look only at truthful revelation mechanisms. Let’s formalize that: consider 
![{x \in [0,1]^n}](http://s0.wp.com/latex.php?latex=%7Bx+%5Cin+%5B0%2C1%5D%5En%7D&bg=T&fg=000000&s=0 "{x \in [0,1]^n}")



 = x_i v_i - p_i}")

Let’s describe a general mechanism: in this mechanism each player has a set of strategies, say 

}")
}")
Let 

}")
Given a complicated mechanism ![{x: \Theta \rightarrow [0,1]^n}](http://s0.wp.com/latex.php?latex=%7Bx%3A+%5CTheta+%5Crightarrow+%5B0%2C1%5D%5En%7D&bg=T&fg=000000&s=0 "{x: \Theta \rightarrow [0,1]^n}")


 = x(\theta_1(v_1), \hdots, \theta_n(v_n))")
 = p(\theta_1(v_1), \hdots, \theta_n(v_n))")
It is not hard to see that if the mechanism is }")


“God help us if we ever take the theater out of the auction business or anything else. It would be an awfully boring world.” (A. Alfred Taubman, Chairman, Sotheby’s Galleries)
So, we can restrict our attention to mechanims in the form ![{x : V \rightarrow [0,1]^n}](http://s0.wp.com/latex.php?latex=%7Bx+%3A+V+%5Crightarrow+%5B0%2C1%5D%5En%7D&bg=T&fg=000000&s=0 "{x : V \rightarrow [0,1]^n}")

}")
}")



Theorem 1 An auction is truthful if and only if, for all possible probability distributions over values given by
, …,
we have
is monotone non-decreasing
where
 = \int p_i(v_i, v_{-1}) f_{-i}(v_{-i}) dv_{-i}}")
Revenue Equivalence
The second main tool to reason about mechanisms concerns the revenue of the mechanism: it is Myerson’s Revnue Equivalence Principle, which roughly says that the revenue under a truthful mechanism depends only on the allocation and not on the payment function. This is somehow expected by the last theorem, since we showed that when a mechanism is truthtful, the payments are totally dependent on }")
The profit of the auctioneer is given by  f(v) dv}")
}")
 f_i(v_i) dv_i = \\&= \sum_{i=0}^n \int_{V_i} \left( v_i x_i(v_i) - \int_0^{v_i} x_i(z) dz \right) f_i(v_i) dv_i \end{aligned}")
We can invert the order of the integration in the second part, getting:
 f_i(v_i) dz dv_i &= \int_{V_i} \int_{v_i}^{\infty} x_i(z) f_i(v_i) dv_i dz = \\ &= \int_{V_i} x_i(z) (1 - F_i(z)) dz \\ \end{aligned}")
So, we can rewrite profit as:
![\displaystyle \text{profit} = \sum_{i=0}^n \int_V \left[ 1 - \frac{1 - F_i(v_i)}{f_i(v_i)} \right] x_i(v_i) f(v) dv](http://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Ctext%7Bprofit%7D+%3D+%5Csum_%7Bi%3D0%7D%5En+%5Cint_V+%5Cleft%5B+1+-+%5Cfrac%7B1+-+F_i%28v_i%29%7D%7Bf_i%28v_i%29%7D+%5Cright%5D+x_i%28v_i%29+f%28v%29+dv+&bg=T&fg=000000&s=0 "\displaystyle \text{profit} = \sum_{i=0}^n \int_V \left[ 1 - \frac{1 - F_i(v_i)}{f_i(v_i)} \right] x_i(v_i) f(v) dv")
And that proves the following result:
Theorem 2 The seller’s expected utility from a truthful direct revelation mechanism depends only on the assignment function
.
Now, to implement a revenue-maximizing mechanism we just need to find 
- Assume that the values of the bidders are drawn from distribution and
- Bidders have fixed values
- The distributions exist but they are unknown by the mechanism designer. In this case, he wants to design a mechanism that provided good profit guaranteed against all possible distributions. The profit guarantees need to be established accourding to some benchmark. This is called prior-free mechanism design.
More references about Mechanism Design can be found in these lectures by Jason Harline, in the original Myerson paper or in the Algorithmic Game Theory book.
 . We want to attribute labels in
. We want to attribute labels in  to the elements of
to the elements of  has associated with it a subset
has associated with it a subset  of labels it can be assigned. Each element can receive at most
of labels it can be assigned. Each element can receive at most  labels. Second, there is a collection
labels. Second, there is a collection  of subsets of
of subsets of  , there must be one label
, there must be one label  that is assigned to all elements in
that is assigned to all elements in  . For each element in
. For each element in  to violate this constraint.
to violate this constraint.![{\sum_{S \in \mathcal{C}} w_S Pr[S \text{ is violated}]}](http://s0.wp.com/latex.php?latex=%7B%5Csum_%7BS+%5Cin+%5Cmathcal%7BC%7D%7D+w_S+Pr%5BS+%5Ctext%7B+is+violated%7D%5D%7D&bg=T&fg=000000&s=0 "{\sum_{S \in \mathcal{C}} w_S Pr[S \text{ is violated}]}") . Let’s formulate this is an integer program. For that, the first thing we need are decision variables: let
. Let’s formulate this is an integer program. For that, the first thing we need are decision variables: let  be a
be a  -variable indicating if label
-variable indicating if label  mean that the label
mean that the label  mean that set
mean that set ")
 are
are  -variables then the formulation corresponds to the original problem. Now, let’s relax it to a Linear Program and interpret those as probabilities. The rounding procedure we use is a generalization of the one in
-variables then the formulation corresponds to the original problem. Now, let’s relax it to a Linear Program and interpret those as probabilities. The rounding procedure we use is a generalization of the one in }") and
and ![{t \sim \text{Uniform}([0,1])}](http://s0.wp.com/latex.php?latex=%7Bt+%5Csim+%5Ctext%7BUniform%7D%28%5B0%2C1%5D%29%7D&bg=T&fg=000000&s=0 "{t \sim \text{Uniform}([0,1])}") and assign label
and assign label  . In the end, pick the
. In the end, pick the  , where
, where  .
.^k}") .
. ![\displaystyle q = \sum_{i \in L} \frac{1}{\vert L \vert} Pr[S \text{is all labeled with } i \text{ in iteration } j]](http://s0.wp.com/latex.php?latex=%5Cdisplaystyle+q+%3D+%5Csum_%7Bi+%5Cin+L%7D+%5Cfrac%7B1%7D%7B%5Cvert+L+%5Cvert%7D+Pr%5BS+%5Ctext%7Bis+all+labeled+with+%7D+i+%5Ctext%7B+in+iteration+%7D+j%5D&bg=T&fg=000000&s=0 "\displaystyle q = \sum_{i \in L} \frac{1}{\vert L \vert} Pr[S \text{is all labeled with } i \text{ in iteration } j]")
 , all elements are labeled with
, all elements are labeled with  for all
for all  , so the probability is
, so the probability is  . So, we have:
. So, we have:
 , therefore:
, therefore:


^j = \frac{q}{p} \cdot \frac{ 1 - \left( \frac{p-q}{p} \right)^k }{1 - \frac{p-q}{p} } = 1 - \left( 1 - \frac{q}{p} \right)^k")
 and
and  to obtain the desired result.
to obtain the desired result. 
^k \leq e^{-a} \leq 1 - \frac{a}{2}")
 , it must also represent a good partition of the graph. Therefore I ploted the same graph as in
, it must also represent a good partition of the graph. Therefore I ploted the same graph as in  with the coordinates
with the coordinates , x_n(v))") where
where  is the eigenvector corresponding to the
is the eigenvector corresponding to the  -th eigenvalue. The first eigenvalues are actually very close to
-th eigenvalue. The first eigenvalues are actually very close to  (as expected),
(as expected),  ,
,  ,
,  ,
,  , … For my suprise, plotting
, … For my suprise, plotting  Also, I looked at
Also, I looked at ") are very good representatives of their respective clusters. In that first graph (in the other blog post), we got a good separation of my high-school friends (in green) and my undergrad friends (in blue). The nodes in the extreme right are my friends I used to hang out more with in college – they are people that are definitely in that cluster. The same about the friends in the extreme left, they are definitely in the other cluster.
are very good representatives of their respective clusters. In that first graph (in the other blog post), we got a good separation of my high-school friends (in green) and my undergrad friends (in blue). The nodes in the extreme right are my friends I used to hang out more with in college – they are people that are definitely in that cluster. The same about the friends in the extreme left, they are definitely in the other cluster. See how all the nodes that were somehow “important” in the last two graphs all collapse to the same place and now we are trying to sort the other nodes. How far can we go? Is there some clean recursive way of extracting multiple (possible overlapping) communities in those large graphs just looking in the local neighborhood? I haven’t reviewed much of the literature yet.
See how all the nodes that were somehow “important” in the last two graphs all collapse to the same place and now we are trying to sort the other nodes. How far can we go? Is there some clean recursive way of extracting multiple (possible overlapping) communities in those large graphs just looking in the local neighborhood? I haven’t reviewed much of the literature yet.![\lambda_i \in [-1,1]](http://s0.wp.com/latex.php?latex=%5Clambda_i+%5Cin+%5B-1%2C1%5D&bg=T&fg=000000&s=0 "\lambda_i \in [-1,1]") , but how are they distributed in this interval. The largest eigenvalue is
, but how are they distributed in this interval. The largest eigenvalue is  . The next plot shows the distribution:
. The next plot shows the distribution: Most of the eigenvalues are accumulated on the positive side (this graph really seems far from being bipartite). Another interesting question if: how can we interpret the shape of this curve. Which characteristics from the graph can we get? I still don’t know how to answer this questions, but I think
Most of the eigenvalues are accumulated on the positive side (this graph really seems far from being bipartite). Another interesting question if: how can we interpret the shape of this curve. Which characteristics from the graph can we get? I still don’t know how to answer this questions, but I think ") in a graph and got the following pattern:
in a graph and got the following pattern: This seems like a nice symmetric pattern and there should be a reason for that. I don’t know in what extent this is a property of real world graphs or from graphs in general. There is
This seems like a nice symmetric pattern and there should be a reason for that. I don’t know in what extent this is a property of real world graphs or from graphs in general. There is  for the first
for the first  eigenvalues. They claim the eigenvalues are close to
eigenvalues. They claim the eigenvalues are close to  where
where  is the
is the ") and
and  Even though they are not a power-law, they still seem to have a similar shape, which I can’t exacly explain right now. Papadimitrou suggests that the fact that
Even though they are not a power-law, they still seem to have a similar shape, which I can’t exacly explain right now. Papadimitrou suggests that the fact that  is a negative result, since
is a negative result, since  seems to be reflecting only a local property of the graph. Here it seems to be following a similar pattern, however, we saw that we can get some nice global and structural properties from that, so it doesn’t seem to be reflecting only local properties.
seems to be reflecting only a local property of the graph. Here it seems to be following a similar pattern, however, we saw that we can get some nice global and structural properties from that, so it doesn’t seem to be reflecting only local properties.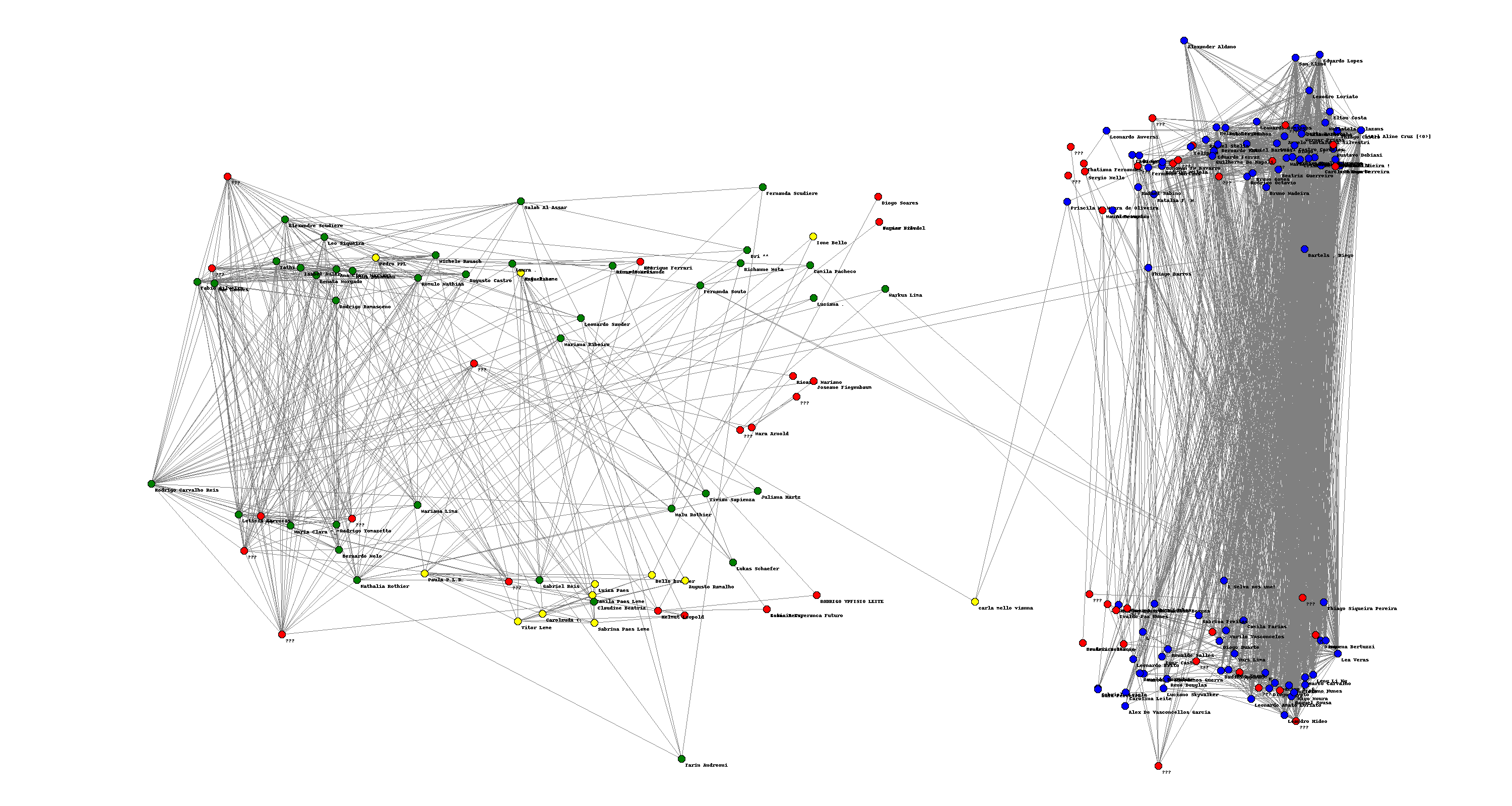{kind=link}